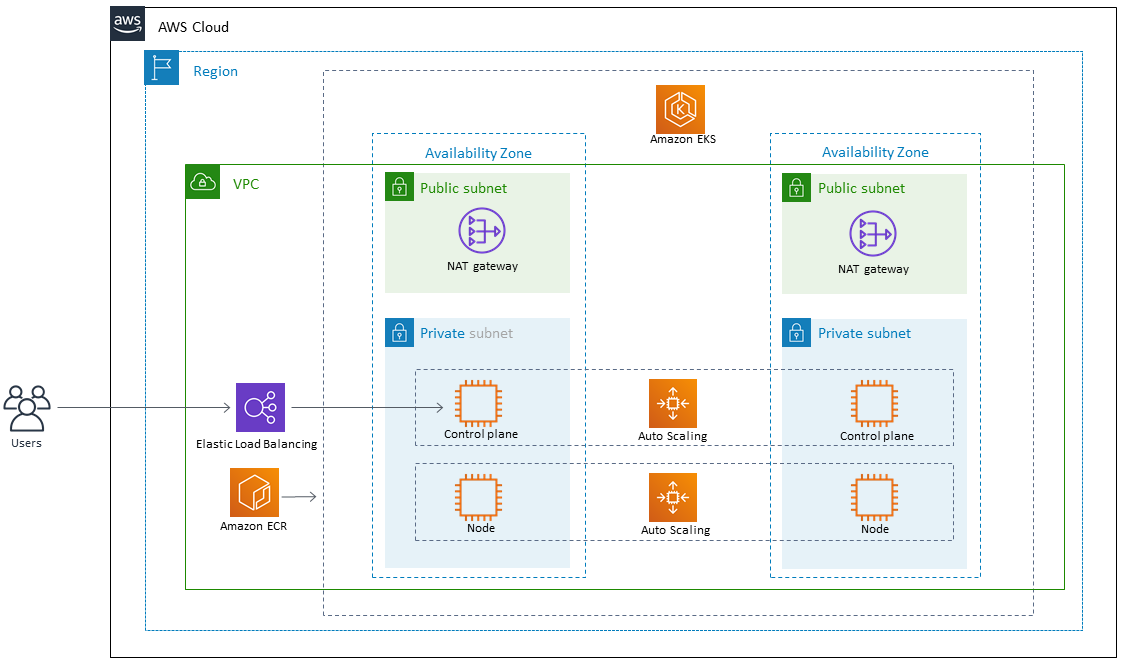
Designed and implemented a cloud-native microservices architecture on AWS EKS to modernize a monolithic e-commerce application. The platform improved scalability, deployment frequency by 300%, and reduced infrastructure costs by 35% through efficient auto-scaling and spot instance utilization.
Key Responsibilities & Achievements
-
Architecture Design: Led the migration from EC2-based monolith to 12+ containerized microservices using Domain-Driven Design principles.
-
Infrastructure as Code: Provisioned EKS clusters, VPCs, and supporting services using Terraform (2,500+ lines of reusable modules).
-
GitOps Deployment: Implemented ArgoCD for declarative, automated deployments across dev/staging/prod environments.
-
Service Mesh: Integrated Istio for advanced traffic management (canary releases, A/B testing) and observability.
-
CI/CD Pipeline: Built GitLab CI pipelines with multi-stage builds, security scanning (Trivy, Checkov), and automated rollback.
-
Observability Stack: Deployed Prometheus, Grafana, and Loki for centralized monitoring, logging, and alerting.
-
Cost Optimization: Achieved 35% cost reduction via Cluster Autoscaler, Karpenter for spot instances, and rightsizing recommendations.
Technical Stack
-
Container Orchestration: Amazon EKS, Helm, Kustomize
-
Infrastructure: Terraform, AWS (VPC, RDS, ElastiCache, S3)
-
CI/CD: GitLab CI, ArgoCD, Docker
-
Monitoring & Security: Prometheus, Grafana, Istio, AWS GuardDuty, Falco
-
Databases & Messaging: PostgreSQL (RDS), Redis (ElastiCache), Amazon MSK (Kafka)
Impact & Results
-
99.95% Uptime: Improved system reliability with zero-downtime deployments
-
Faster Releases: Reduced deployment time from 2 hours to 15 minutes
-
Enhanced Security: Implemented network policies, pod security standards, and secret management with Vault
-
Team Enablement: Created developer self-service portals for namespace provisioning and deployment tracking
**Technical insights revealed that while Kubernetes excels for stateless workloads, we learned to preserve managed services like RDS for stateful data due to operational complexity. Proactive safeguards such as Pod Disruption Budgets were essential for production resilience, and we underestimated the intricacies of AWS IAM and VPC networking, which we later templated with Terraform to save significant time. Crucially, cost visibility from day one was non-negotiable, as initial over-provisioning led to substantial waste, underscoring that architectural decisions must prioritize simplicity, resilience, and financial accountability over technical novelty.**
Process & Collaboration
-
GitOps Adoption Requires Cultural Shift
-
Developers initially struggled with ArgoCD’s declarative approach versus imperative kubectl commands. We created extensive documentation and interactive workshops to ease the transition. Lesson: Technology changes must be accompanied by training and gradual adoption.
-
-
Observability Is More Than Tools
-
Despite deploying Prometheus and Grafana, we initially lacked meaningful alerts. We shifted to a “golden signals” approach (latency, traffic, errors, saturation) and involved developers in defining SLOs/SLIs. Lesson: Focus on outcomes (actionable alerts) over tool deployment.
-
-
Security Cannot Be Bolted On
-
Our initial pipeline only had security scanning at the final stage. Shifting left with pre-commit hooks, image scanning in CI, and admission controllers prevented 15+ vulnerabilities from reaching production. Lesson: Security must be integrated throughout the DevOps lifecycle.
-
-
Documentation as Code
-
Knowledge silos formed around our complex routing rules and Istio configurations. We started maintaining living documentation in Git (READMEs, architecture decision records) alongside the code. Lesson: If it’s not documented in version control, it doesn’t exist.
-
Strategic Takeaways
-
Start Simple, Then Scale
-
Our first attempt at service mesh (Istio) was overwhelming. We succeeded by implementing it incrementally—starting with just ingress, then adding traffic splitting, and finally security policies over 3 months.
-
-
Vendor Lock-in Considerations
-
While EKS provided rapid deployment, we made conscious decisions to use CNCF-standard tools (Prometheus, Fluent Bit, etc.) where possible. This paid off when we later created a hybrid cloud proof-of-concept.
-
Final Reflection: The most successful architectural decisions balanced cutting-edge technology with operational simplicity. Sometimes a managed service (RDS, ElastiCache) proved more valuable than the “cool” Kubernetes-native alternative. The key was aligning technology choices with business outcomes—reliability, velocity, and cost—rather than technical novelty alone